关注微信公众号 “程序员小胖” 每日技术干货,第一时间送达!
引言
在当今这个数据密集、服务分布的数字时代,设计高效且可靠的分布式系统成为了技术领域的核心挑战之一。提及分布式系统设计的理论基石,CAP理论——即一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)的不可能三角,早已成为人尽皆知的经典原则。然而,在实际应用中,强一致性往往伴随着可用性的牺牲,这对于许多追求高响应速度和用户体验的应用场景而言,无疑是一大难题。正是在这样的背景下,BASE理论应运而生,为分布式系统的设计提供了一种全新的视角与解决方案。接下来 我们来探寻BASE理论与CAP的区别
BASE理论
Base理论(Basically Available, Soft state, Eventual consistency),即基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)。
Base 理论的核心思想是最终一致性,即使无法做到强一致性(Strong Consistency),但每个应用都
可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual Consistency)。
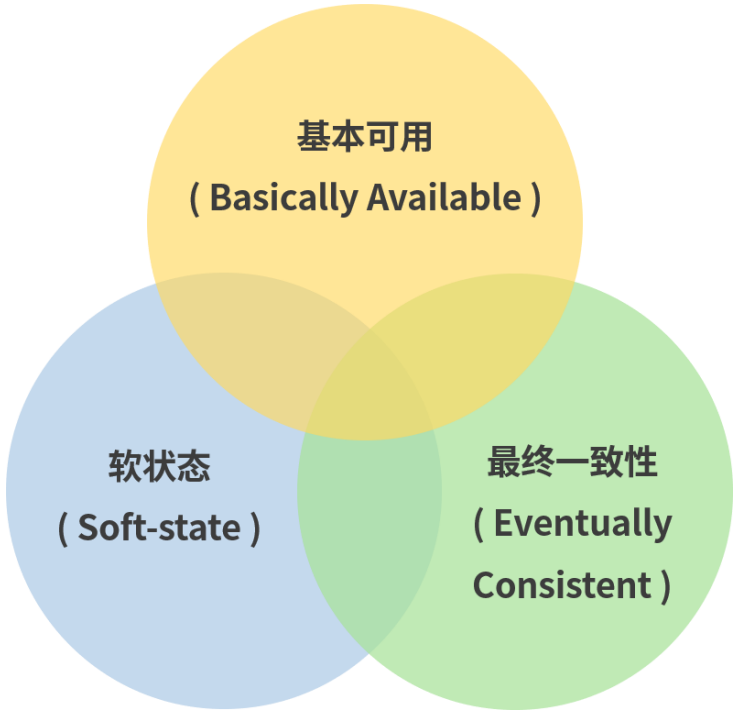
基本可用(Basically Available)
基本可用比较好理解,就是不追求 CAP 中的**「任何时候,读写都是成功的」**,而是系统能够基本运行,一直提供服务。基本可用强调了分布式系统在出现不可预知故障的时候,允许损失部分可用性,相比正常的系统,可能是响应时间延长,或者是服务被降级。
举个例子,在双十一秒杀活动中,如果抢购人数太多超过了系统的 QPS 峰值,可能会排队或者提示限流,这就是通过合理的手段保护系统的稳定性,保证主要的服务正常,保证基本可用。
软状态(Soft State)
软状态可以对应 ACID 事务中的原子性,在 ACID 的事务中,实现的是强一致性,要么全做要么不
做,所有用户看到的数据一致。其中的原子性(Atomicity)要求多个节点的数据副本都是一致的,强调数据的一致性。原子性可以理解为一种“硬状态”,软状态则是允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
最终一致性(Eventually Consistent)
数据不可能一直是软状态,必须在一个时间期限之后达到各个节点的一致性,在期限过后,应当保证
所有副本保持数据一致性,也就是达到数据的最终一致性。在系统设计中,最终一致性实现的时间取决于网络延时、系统负载、不同的存储选型、不同数据复制
方案设计等因素。
使用场景分析
消息队列系统
消息队列系统是分布式系统中实现异步处理、解耦和提高系统扩展性的重要组件。在消息队列系统中应用BASE理论,尤其是在确保最终一致性方面,是一种常见的做法。如Kafka、RabbitMQ,允许消息的顺序和实时性有所偏差,但最终要保证所有消息都被消费。
import com.rabbitmq.client.*;
public class MessageProducer {
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
// RabbitMQ服务器地址
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明队列
channel.queueDeclare("base_queue", true, false, false, null);
String message = "Hello, BASE theory in Action!";
channel.basicPublish("", "base_queue", null, message.getBytes());
System.out.println(" [x] Sent: '" + message + "'");
} catch (IOException | TimeoutException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们创建了一个名为base_queue的消息队列,并发送了一条消息。消息队列将保证消息的传递,即使在网络分区的情况下,消息也不会丢失,从而实现基本可用和最终一致性。
import com.rabbitmq.client.*;
import java.io.IOException;
public class MessageConsumer {
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
// RabbitMQ服务器地址
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明队列
channel.queueDeclare("base_queue", true, false, false, null);
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received: '" + message + "'");
// 可以在这里处理消息,例如更新数据库或触发其他业务逻辑
};
channel.basicConsume("base_queue", true, deliverCallback, consumerTag -> { });
} catch (IOException | TimeoutException | ShutdownSignalException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们创建了一个消费者,它订阅了base_queue队列。当消息到达队列时,消费者将接收并处理这些消息。消费者可以容忍短暂的网络问题或服务故障,因为RabbitMQ会确保消息不会丢失,从而实现软状态和最终一致性。
注意事项
- 应用中,需要考虑消息的持久化、确认机制和重试策略,以确保消息的可靠传递和处理。
- 其他分布式系统组件一起使用,如分布式缓存、数据库等,以实现整个系统的高可用和一致性。
- 队列系统时,应根据业务需求和系统特点来权衡消息的传递速度、持久性和一致性。
布式缓存系统
如Redis集群,允许缓存数据存在短暂的不一致性,但最终要保证数据的一致性。
在Redis集群中应用BASE理论主要涉及到如何处理数据的最终一致性,尤其是在面对网络分区、节点故障等分布式系统常见问题时。Redis集群通过数据分片(sharding)和复制(replication)来提高可用性和可扩展性,但为了保证最终一致性,通常需要在应用层面做一些额外的工作。
import redis.clients.jedis.Jedis;
public class RedisClusterExample {
public static void main(String[] args) {
// 连接到Redis集群中的一个节点
Jedis jedis = new Jedis("localhost", 6379);
// 写入数据,假设key和value都是字符串类型
String key = "myKey";
String value = "myValue";
jedis.set(key, value);
System.out.println("Data written to Redis: " + key + " = " + value);
// 关闭连接
jedis.close();
}
}
注意事项
- Redis集群的自动故障转移和数据复制机制可以处理大多数的一致性问题,但在某些复杂的场景下,可能需要应用层的额外逻辑来保证数据的最终一致性。
- 在设计使用Redis集群的系统时,应该考虑到数据的读写分布、节点的故障转移和数据的迁移等问题。
- 使用Redis集群时,应该监控集群的状态,包括节点的健康、复制的延迟等,以便于及时发现和解决问题。
分布式数据库
如Cassandra,允许写入数据后,副本之间的同步存在延迟,但最终要保证数据的一致性。
在分布式数据库中应用BASE理论主要关注于如何通过异步复制和最终一致性来保证系统的高可用性和可扩展性,即使在网络分区或节点故障的情况下。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
public class CassandraBaseExample {
public static void main(String[] args) {
// 创建Cluster实例连接到Cassandra集群
Cluster cluster = Cluster.builder().addContactPoint("localhost").build();
Session session = cluster.connect();
// 在'test' keyspace中创建一个'users'表
session.execute("CREATE KEYSPACE IF NOT EXISTS test WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3' };");
session.execute("CREATE TABLE IF NOT EXISTS test.users (id UUID PRIMARY KEY, name text)");
// 插入数据
ResultSet resultSet = session.execute("INSERT INTO test.users (id, name) VALUES (uuid(), 'John Doe')");
System.out.println("Data inserted: " + resultSet.toString());
// 读取数据
Row row = session.execute("SELECT * FROM test.users").one();
System.out.println("Read data: " + row.toString());
// 关闭Session和Cluster
session.close();
cluster.close();
}
}
注意事项
- Cassandra的写入操作默认是本地事务,保证了单个节点上数据的一致性。通过配置副本因子(replication_factor),Cassandra可以在集群中的多个节点之间异步复制数据。
- Cassandra的轻量级事务提供了基本的一致性保证,但在高负载或网络问题下,可能需要额外的策略来处理一致性问题。
- 在设计分布式数据库系统时,应该考虑到数据的读写一致性、节点的故障转移和数据的迁移等问题。
电商平台
在电商平台中BASE理论的应用 通常涉及到如何处理订单、支付、库存和物流等关键业务流程的数据一致性问题。BASE理论特别适用于可以容忍短暂不一致性,但需要保证最终数据一致性的场景。
发送订单创建事件到消息队列:
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class OrderService {
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
channel.queueDeclare("order_created", true, false, false, null);
String message = "Order created with ID 123";
channel.basicPublish("", "order_created", null, message.getBytes());
System.out.println(" [x] Sent: '" + message + "'");
} catch (IOException | TimeoutException e) {
e.printStackTrace();
}
}
}
监听订单创建事件并更新库存
import com.rabbitmq.client.*;
import java.io.IOException;
public class InventoryService {
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println("Received message: " + message);
// 假设这是一个异步的库存更新操作
updateInventory(message);
// 确认消息已处理
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
};
channel.basicConsume("order_created", true, deliverCallback, consumerTag -> { });
} catch (IOException | TimeoutException | ShutdownSignalException e) {
e.printStackTrace();
}
}
private static void updateInventory(String message) {
// 根据订单ID更新库存的业务逻辑
// 这里仅为示例,实际应用中需要根据订单详情进行库存更新
System.out.println("Inventory updated for order: " + message);
}
}
注意事项
- 在实际的电商平台中,还需要考虑更多的业务逻辑和异常处理,如订单取消、支付失败等情况下的库存回滚。
- 消息队列的使用需要合理配置,包括消息的持久化、消费确认机制和重试策略等。
- 为了确保数据的最终一致性,可能需要引入分布式事务或事件溯源等高级技术。
内容分发网络(CDN)
内容分发网络(CDN)是一种分布式系统,用于加速网络内容的分发,提高用户体验。在CDN中应用BASE理论,主要是为了处理节点间的数据一致性和可用性问题。在数据分发到边缘节点时,可以容忍数据的短暂不一致,但最终要保证所有节点的数据一致。
下面是一个简化的代码示例,模拟CDN中的数据同步过程。我们假设有一个源站和多个边缘节点,边缘节点会从源站异步地拉取数据。
源站(模拟):
import java.io.*;
import java.net.*;
public class SourceServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8000);
System.out.println("Source server is running on port 8000");
while (true) {
Socket socket = serverSocket.accept();
new Thread(() -> {
try (BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(socket.getOutputStream(), true)) {
String data = "<html><body><h1>This is the source data</h1></body></html>";
out.println(data);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}
边缘节点(模拟)
import java.io.*;
import java.net.*;
public class EdgeNode {
private String sourceHost;
private int sourcePort;
public EdgeNode(String host, int port) {
this.sourceHost = host;
this.sourcePort = port;
}
public void syncData() {
try (Socket socket = new Socket(sourceHost, sourcePort);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(new FileWriter("edge_data.html"), true)) {
String line;
while ((line = in.readLine()) != null) {
out.println(line);
}
System.out.println("Data synchronized from source server");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
EdgeNode edgeNode = new EdgeNode("localhost", 8000);
edgeNode.syncData();
}
}
SourceServer模拟了CDN的源站,它在8000端口上监听连接请求,并发送数据给连接的边缘节点。EdgeNode模拟了CDN的边缘节点,它连接到源站并同步数据。为了模拟现实世界中的异步和最终一致性,边缘节点可能会在不同的时间点从源站拉取数据。
注意事项:
- 在实际的CDN系统中,数据同步通常涉及到更复杂的机制,如缓存策略、版本控制、冲突解决等。
- CDN节点通常使用高效的数据传输协议和压缩技术来优化数据同步过程。
- 为了确保数据的安全性,CDN系统可能还需要实现数据加密和认证机制。
结语
在探索分布式系统的广阔天地中,BASE理论不仅为我们绘制了一条通向高可用与最终一致性的实践路径,更是一种哲学,指导我们在复杂多变的现实需求与技术约束间寻求精妙的平衡。它教会我们,面对分布式环境的不确定性,适时放松对即时强一致的执着,转而在软状态与最终一致性中发掘系统的灵活性与韧性。
简而言之,BASE理论是分布式系统设计中的一盏明灯,它照亮了在分区容忍这一不可规避的现实中,如何优雅地妥协与创新,以确保我们的系统能够在风云变幻的网络环境下,依旧稳健前行。最终,每一个分布式应用的构建者都能从中汲取灵感,创造出既能适应快速变化市场需求,又能保障用户优质体验的卓越系统。在这个旅程的终点,我们不仅收获了技术的胜利,更实现了对分布式世界深刻理解的升华。
![[HNOI2003]激光炸弹](https://img-blog.csdnimg.cn/direct/4b9f37466d494471bfd12a444a93d721.png)





![BUUCTF---misc---[BJDCTF2020]纳尼](https://img-blog.csdnimg.cn/direct/531280b5aa2541249d4e44445aaba84a.png)